

HOW CONSISTENT ARE BLACK LIST EVALUATIONS?
128,020 film and TV evaluations over the last five years. We’re publishing our consistency data.

I hear from writers semi-frequently who are convinced that the script evaluation process is a coin flip. They got a pass and then a consider. A 5, then a 7. Or a 6, and then a 4. Two different readers, two different experiences, and they want to know “which one is real?”
It’s a fair question. It’s also one that, as far as I know, no one in this industry has ever answered publicly with data. Not talent agencies. Not film festivals. Not studios. No one who evaluates screenplays or television scripts at scale for a living has ever shown you the numbers on how consistent their readers actually are.
We’re going to.
The Black List just analyzed its most recent five years of film and television evaluation scores — 128,020 evaluations across more than 71,000 projects – with a relatively simple goal: find out how often two independent readers, working separately, with no knowledge of each other’s scores, arrive at the same conclusion about the same script.
Here’s the short answer: most of the time.
THE HEADLINE NUMBERS
When two Black List readers independently evaluate the same screenplay, they score it within one point of each other on overall quality 73.8% of the time. For television pilots, it’s 74.1%.
That’s across 212,673 evaluation pairs for film and 65,227 for television.1 Readers who weren’t assigned together, don’t know what the other person scored, and are evaluating 60 to 120 pages of original creative work on a 10-point scale.
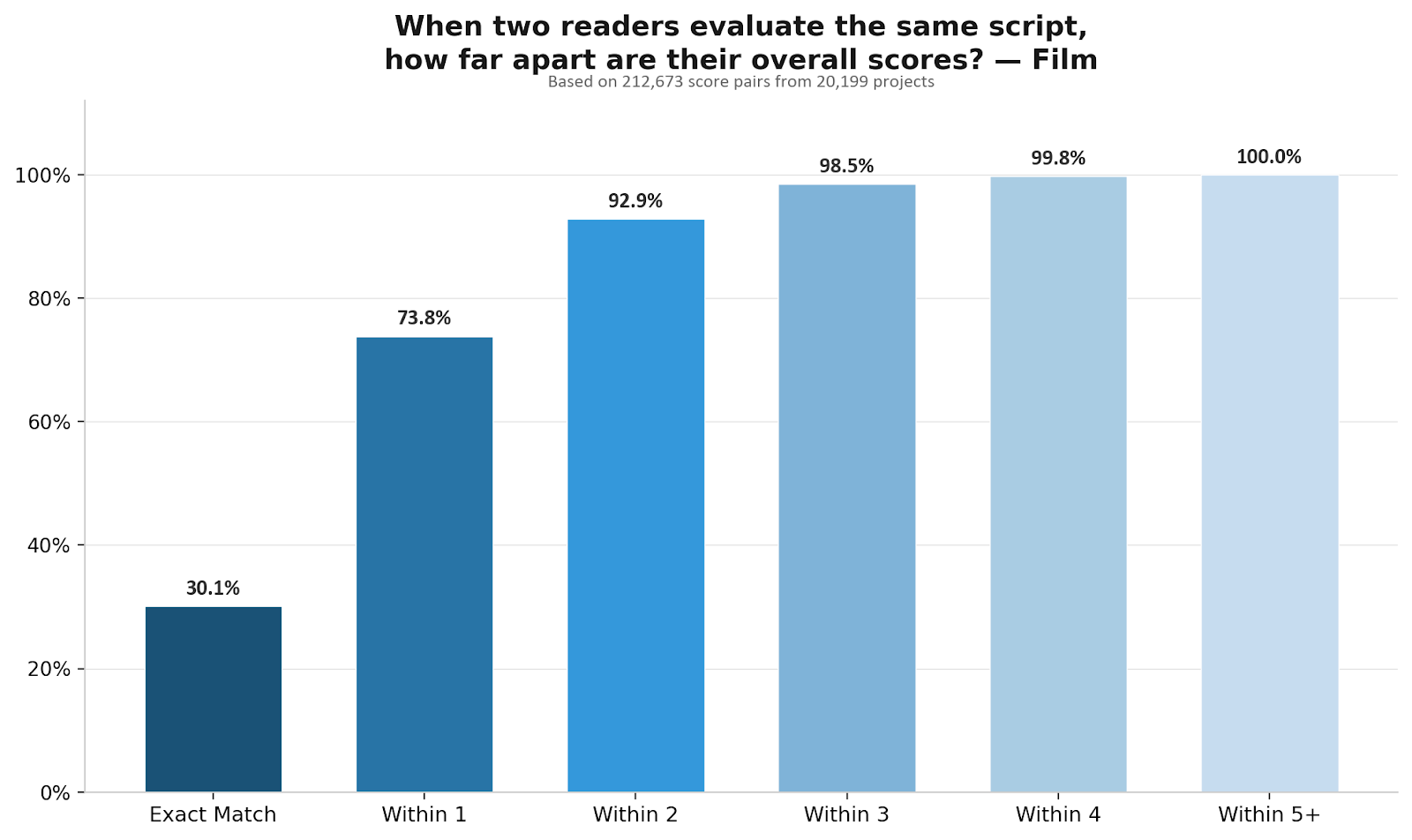
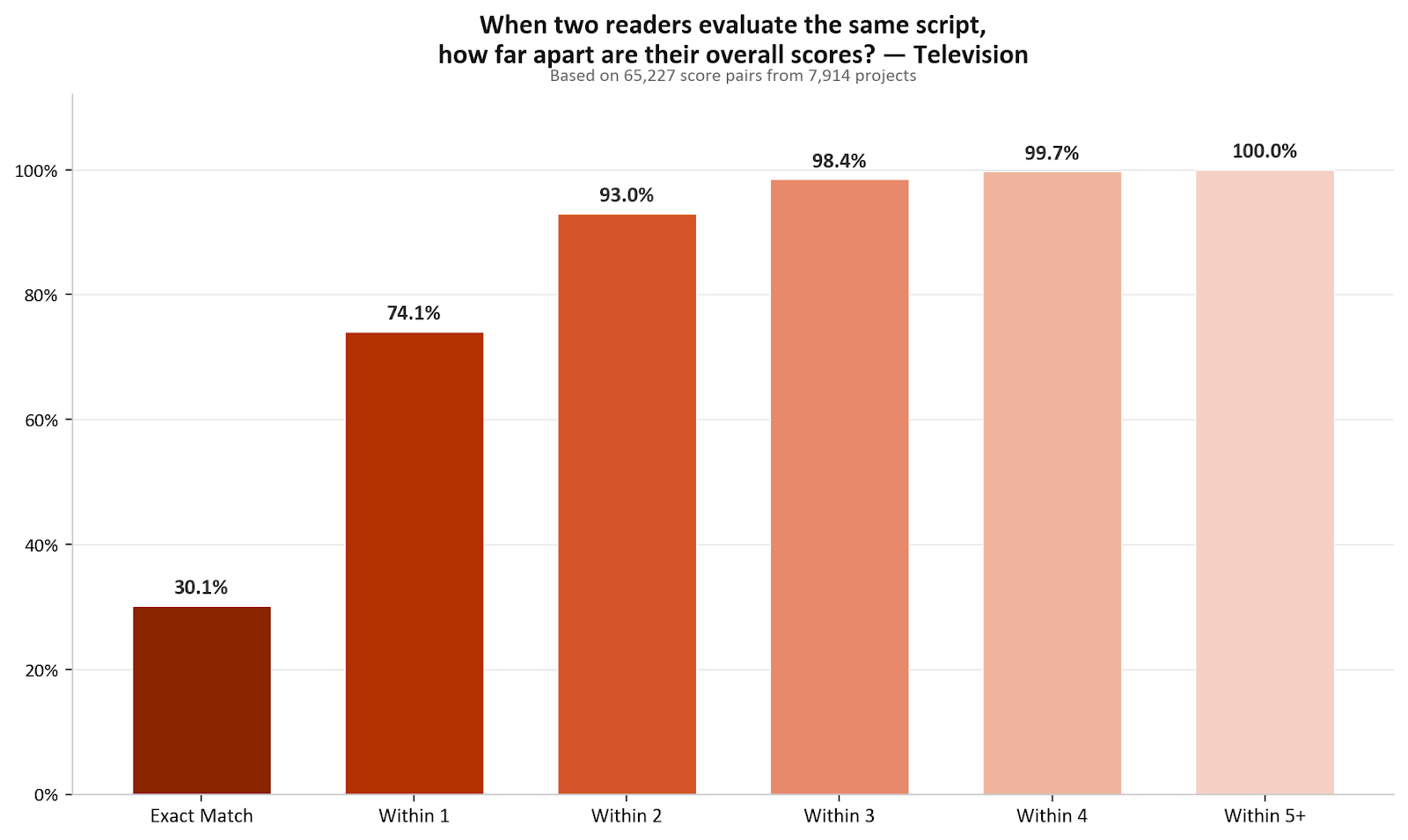
30% of the time, they give the exact same score. Another 44% differ by exactly one point. A 6 and a 7. A 5 and a 6.
A two-point gap — a 5 and a 7, for example — happens about 19% of the time. Three points, about 5.5%. Four or more points: 1.5%. In five years, across 128,020 evaluations, a five-point gap between Black List reader scores almost never happens (~0.25% of all evaluation pairs.)
I know that’s not what it feels like when you’re staring at two scores that don’t match. A 5 and a 7 probably feels like the system is broken, but it just means you’re in the 19% of cases where two qualified readers had a genuine difference of opinion about your work. That happens. It happens in peer review. It happens in festival selection. It happens in agency coverage. (Kate Hagen note here: “Lest we forget Roger Ebert panning BLUE VELVET then including MULHOLLAND DR. among his “Great Movies”, the endless disagreement over LOLITA, Pauline Kael’s negative response to VERTIGO or JAWS or 2001.”) The difference is that we’re the ones telling you that it does, and exactly how often.
HOW DOES THIS COMPARE TO ANYTHING ELSE?
Generally speaking, whenever you ask qualified people to independently assess complex work — a screenplay, a film, a novel, a journal article, a grant proposal — they agree more than chance would predict and less than you’d probably like.
The question that really matters is, do evaluators agree at rates comparable to systems the world already trusts?
In the Black List’s case, they do. And in most cases, they exceed them. The closest public benchmarks we can find are the systems that determine what scientific research gets published.
A meta-analysis of 48 studies covering 19,443 journal manuscripts found mean reliability coefficients ranging from 0.23 to 0.34.2 The Black List’s reliability coefficients are 0.290 for film and 0.366 for television — at or above the average across published peer review studies. Our readers are as consistent as the peer review systems that decide what appears in scientific journals, and I would posit that evaluating a screenplay, where the entire enterprise is subjective, is a harder consistency problem than evaluating a journal article, where at least the methodology and the like can be checked.
STATISTICALLY SPEAKING, HOW PRECISE IS A SINGLE SCORE?
As already mentioned, Black List readers score on a 10-point integer scale. As a result, any single evaluation is inevitably, at best, a rounded judgment, and even highly consistent readers will produce natural variation simply because the scale doesn’t allow for half or smaller grade points. It’s simply the reality of any integer rating system, whether it’s an evaluation platform, a film festival jury score, or agency/studio coverage grade. There is some material amount of uncertainty in a single score. Colloquially speaking, it just be like that.
Here’s what the data says about how quickly that uncertainty resolves.
After a single evaluation, the “true” score — the average you’d get if dozens of qualified readers evaluated the same script — falls within one point of your score about 75% of the time.3 After two evaluations averaged together, that range tightens to about 0.6 points. After three, about 0.4. After four, about 0.25.
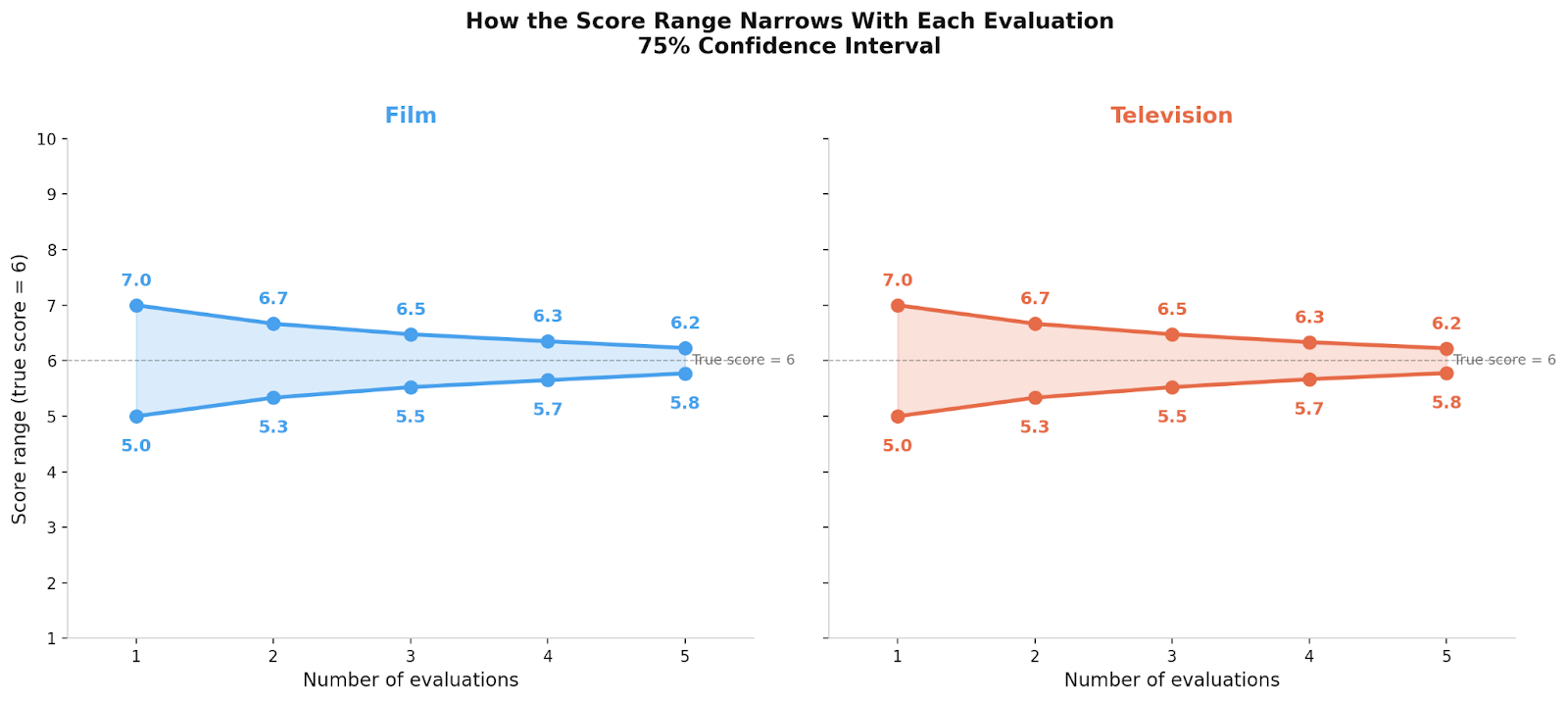
Statistically speaking, the biggest gain comes from the second read. After that, each additional evaluation offers smaller refinements to a picture that’s already coming into focus.
Realistically speaking though, what the data - and common sense - also says is that if you’ve received two or three evaluations and your scores are clustering around a 4 or a 5, more evaluations are incredibly unlikely to change that picture. I’ve said it before and I’ll say it again: You’re almost certainly better off not giving us more of your money for hosting and feedback, spending your time working on your craft and your script, and coming back when you have a better script.
On the flip side: if even a single reader scores your script 8+ overall, we provide a free month of hosting and two free evaluations. Each additional 8+ overall score results in more free hosting and free evaluations (until you’ve received five 8+ overall scores, after which we host the script for free for as long as you’d like.) We do this because the data tells us the signal is real, and we’d rather invest in surfacing great material than ask the writer to pay for confirmation that it’s great.
WHAT READERS AGREE ON - AND WHEN TASTE TAKES OVER
Black List readers score feature scripts and television pilots on six dimensions: overall quality, premise, plot, characters, dialogue, and setting (manuscript evaluations include an additional three dimensions: originality, prose, and themes).
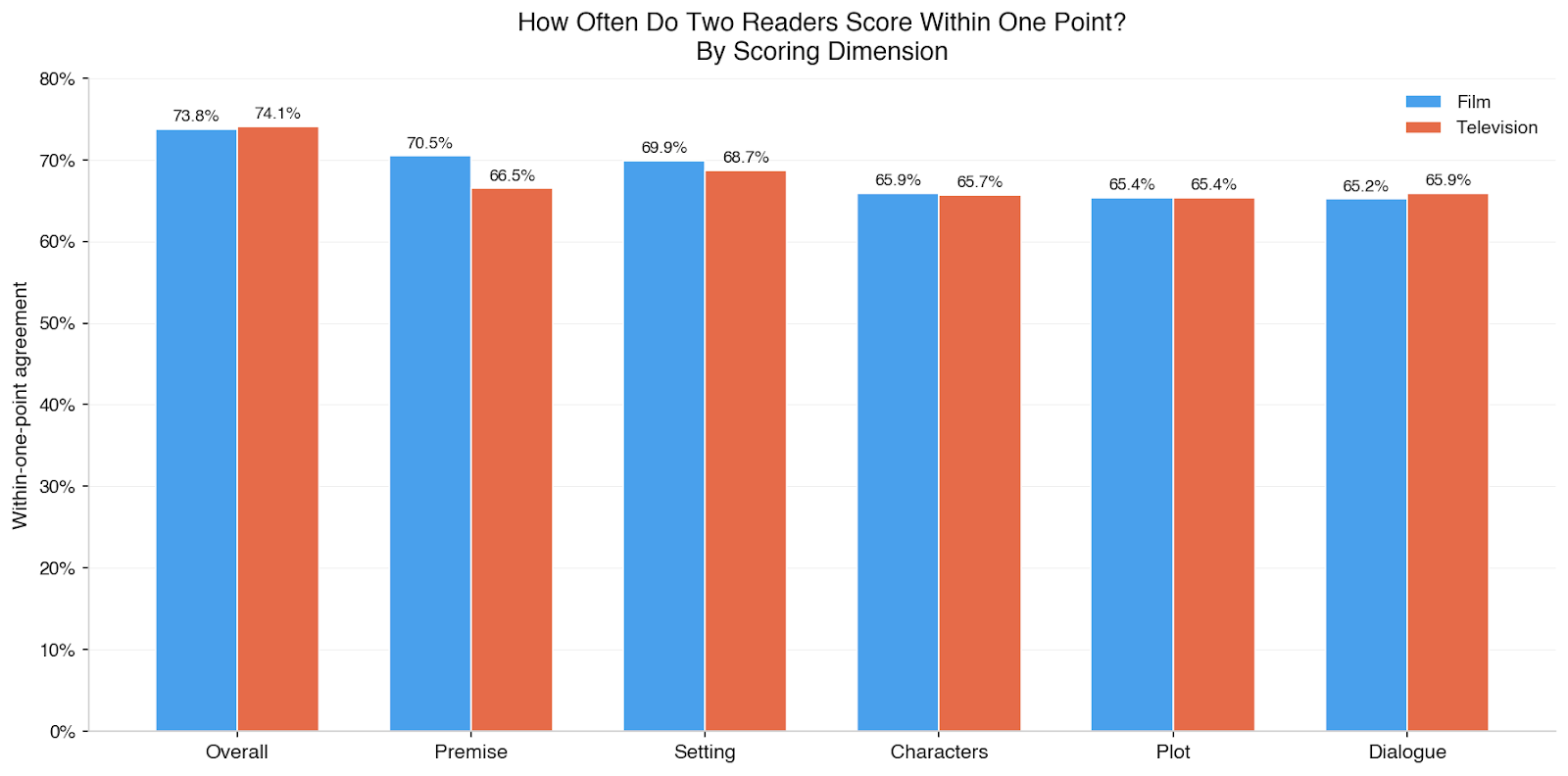
Overall quality is the most reliable dimension for both film and television. Readers converge most on their overall impression of a piece of material — essentially, is this thing working for me? — even when they disagree somewhat about why. This shouldn’t be surprising. Anyone who’s had to evaluate a screenplay - or any long form storytelling - knows how hard it can be to articulate why something didn’t land for you even if you know in your gut that it didn’t.
The data tells us that dialogue, plot, and character are all clustered together as the least reliable dimensions. This tracks with what we’d expect: whether a concept is compelling or a world is vivid are relatively bounded judgments. Whether dialogue sings, whether a plot is well-structured, whether characters feel alive on the page are judgments that are more driven by taste than craft assessment. And taste is supposed to vary.
We also checked whether agreement changes by genre: it doesn’t in any way that matters. Across 31 genres with at least 500 projects, within-one-point agreement on overall quality ranges from 70% to 77%. Genres like action & adventure, action thrillers, and - interestingly - monsters sit near the top. More interpretive genres like psychological sci-fi, slashers & psychos, and comedy thrillers sit near the bottom. But the spread between them is quite narrow. None of those 31 genres breaks out of that 70-77% band. Essentially, your genre isn’t making your scores less reliable.
Notably, two genres people often assume to be particularly polarizing - comedy and horror - don’t appear to be at all, on average. In fact, across all evaluations we’ve done over the last five years in both genres, they’re pretty consistent with the overall dataset.
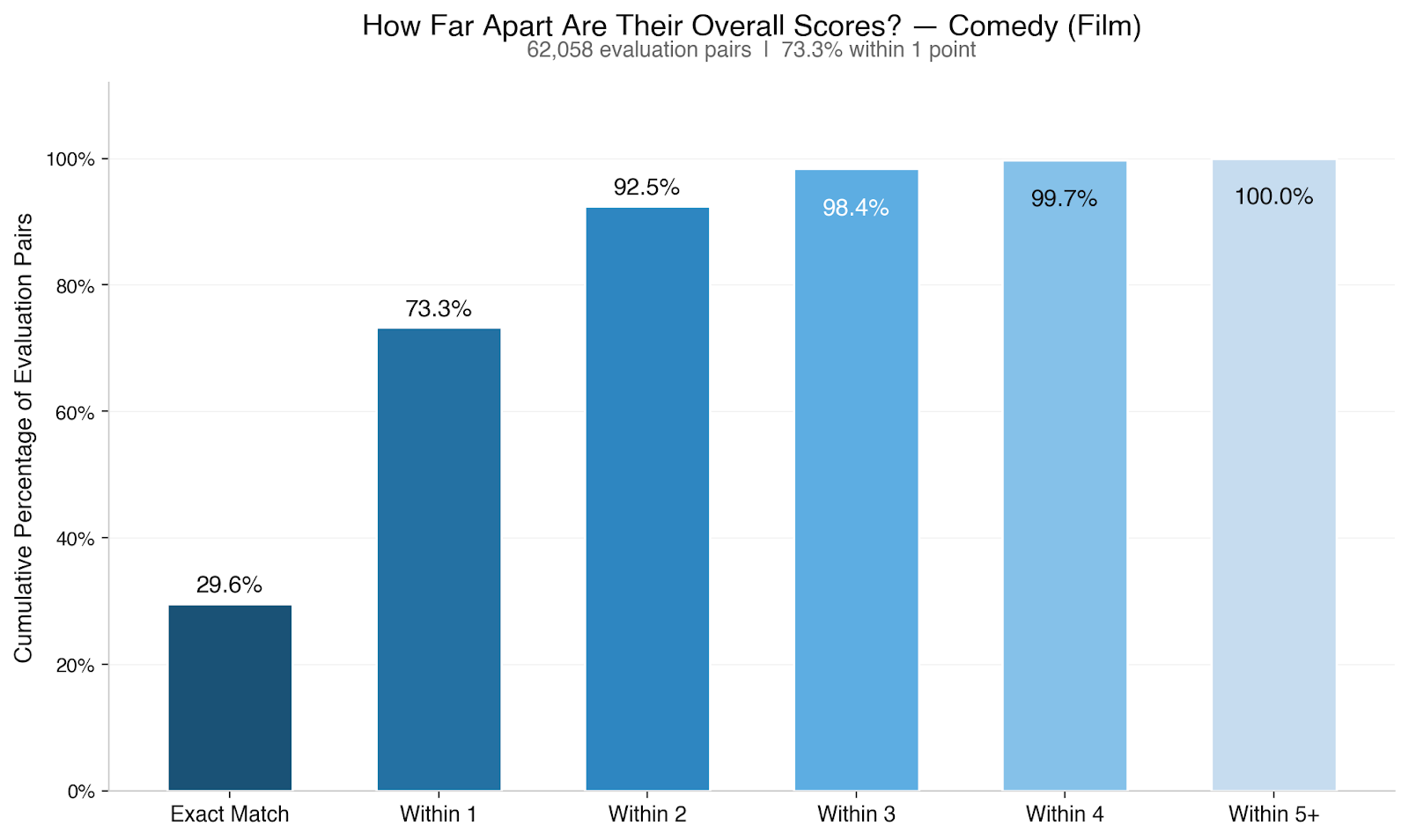
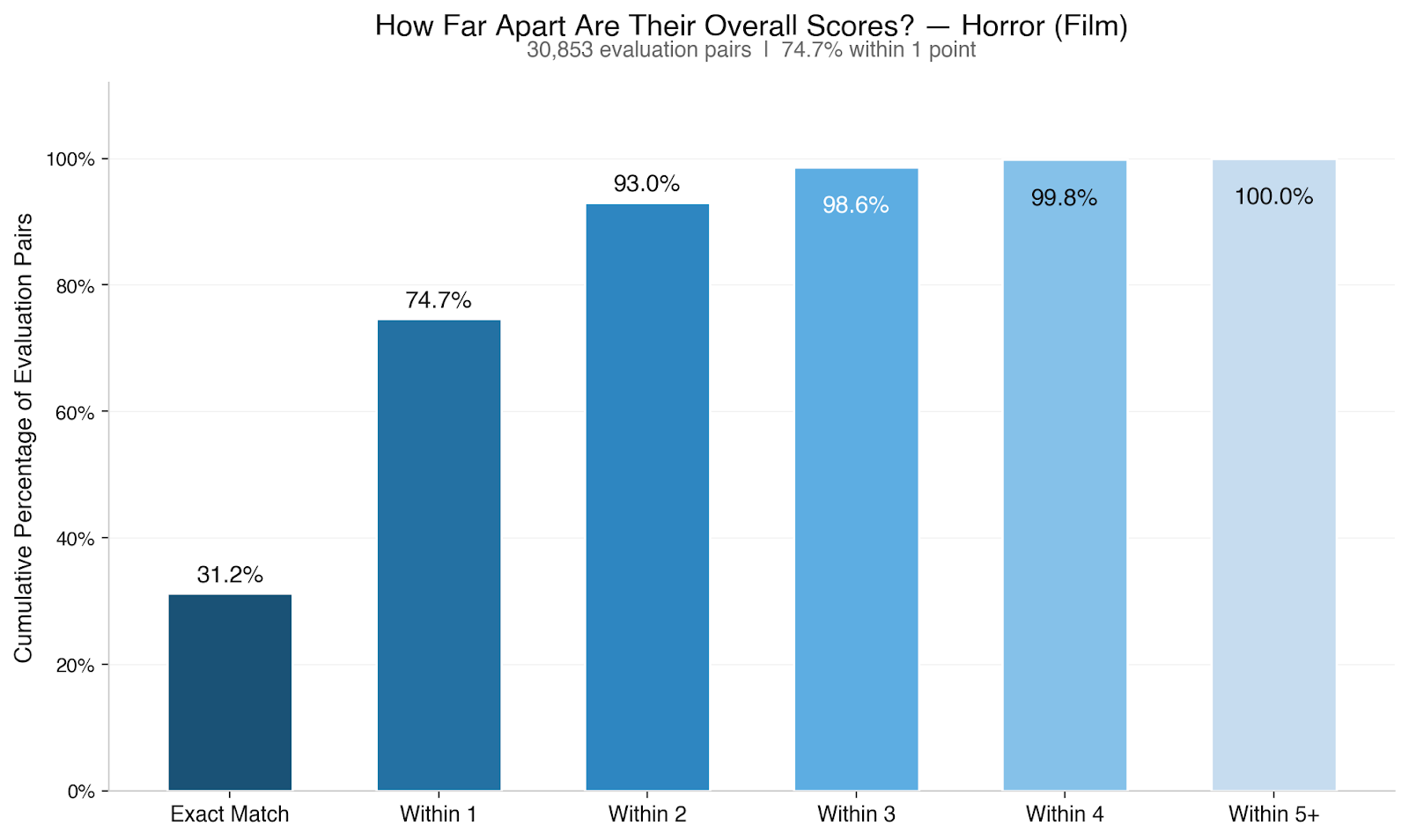
One more pattern worth calling out: the middle-bottom of the quality spectrum — scripts averaging a 4 or 5 — shows weaker agreement than scripts averaging a 6 or 7. Distinguishing between “below average” and “average” appears to be genuinely harder than distinguishing between “good” and “very good.”
WHEN READERS SHARPLY DISAGREE
Roughly a quarter of the time, two readers land more than one point apart on overall quality. When that happens — when you get a 5 and a 7, or a 4 and a 7 — a natural question is: what would a third reader say?
Well, we checked. For scripts with three evaluations where two evaluations diverged by two or more points, we looked at where the third reader landed.4
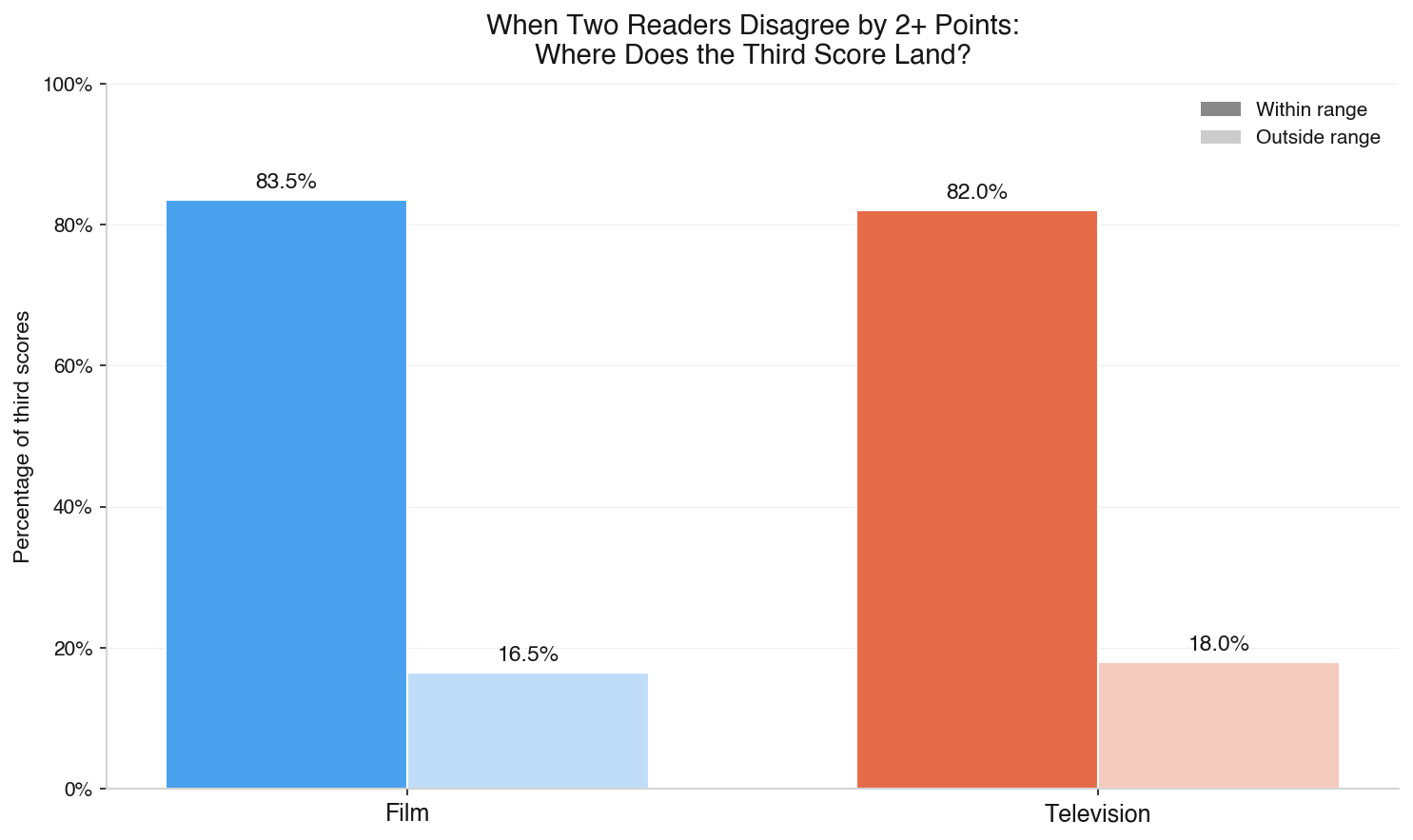
For film, the third score falls within the range set by the first two reads 83.5% of the time. For television, 82.0%. More notably, the third reader doesn’t reliably break the tie in favor of the higher or lower score. What they do is confirm that the truth is somewhere in the middle. Even when two readers disagree meaningfully, they’re usually bracketing reality rather than missing it.
As discussed above in the section about the precision of a single read, when scores differ significantly, the average of three reads is a more precise picture of a script than any individual score, which is also why if a writer receives two successive evaluations that differ by 3 or more points on overall quality, we offer the next evaluation at a significant discount, the exact price we pay our readers. That kind of divergence warrants another data point, and we don’t think the writer should bear the full cost of getting it.
One more thing about disagreement, because I think writers often misread it: A genuine split with one score toward the upper end of the spectrum — a 5 and an 8, for example — is not the same thing as a bad score. It means one reader saw something ambitious and rewarded it while another just wasn’t sure it landed. It means you’ve written something that engages readers enough to divide opinion, and in that division, at least one person feels very positive. Historically speaking (both on the Black List platform and for art in general), that’s a very good thing. Pay attention to that. (And take advantage of the free hosting and free evaluations that come with an 8+ overall score.)
WHAT ALL OF THIS MEANS IF YOU’RE A BLACK LIST INDUSTRY MEMBER
When a script gets high scores from multiple Black List readers, they arrived there independently. They were matched by format expertise, genre interest, and content sensitivity, so every evaluation comes from someone who chose to read in that space and has experience doing it. A high score doesn’t mean they had a good day. It means that they liked the script, and it’s highly likely other people will too.
If you’re using Black List scores to decide what to read (and you should be), the data itself says that’s a very efficient use of your time.
If you’re not, you should fix that: sign up for an industry member account.
IN CLOSING
The Black List starts from a fundamental assumption that all art is subjective. Two smart, qualified people can read the same hundred pages and come away with different impressions of whether it worked. That’s supposed to happen. It’s the way things happen in the real world. The way things happen in Hollywood. And the way they should happen on the Black List.
No one should want our readers - or anyone evaluating art, frankly - to agree on everything (what a boring world that would be.) What we aspire toward at the Black List is relative consistency born of experienced professional readers reading in formats of their expertise and genres of their interest and reading with the same, consistent care.
Writers often wonder whether they should trust our evaluation system. The most honest answer I can give is that we trust it. We trust it enough to invest our own resources every time a reader flags something as outstanding. We trust it enough to tell you when the data says to stop spending your money. And we trust it enough to publish the numbers and let you judge for yourself.
Methodology: All agreement statistics computed using every unique evaluation pair within each project. Reliability measured using the intraclass correlation coefficient, one-way random effects model (ICC(1,1)). Convergence analysis: 100 random shuffles per project for all projects with four or more evaluations. Third-reader analysis: all projects with exactly three evaluations. No evaluations excluded. Dataset: five years of Black List platform evaluations across 50,683 film and 20,531 television projects.
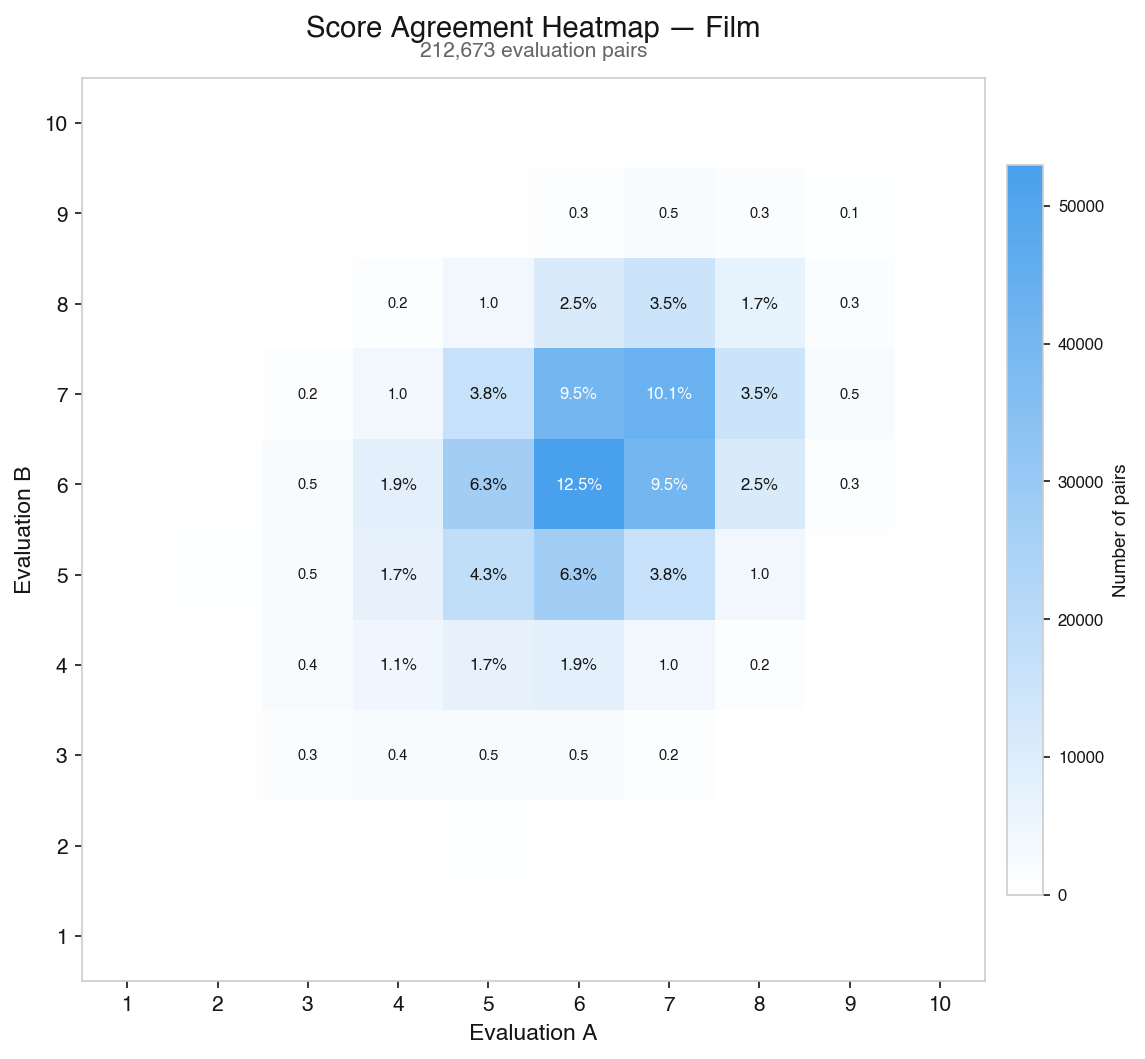
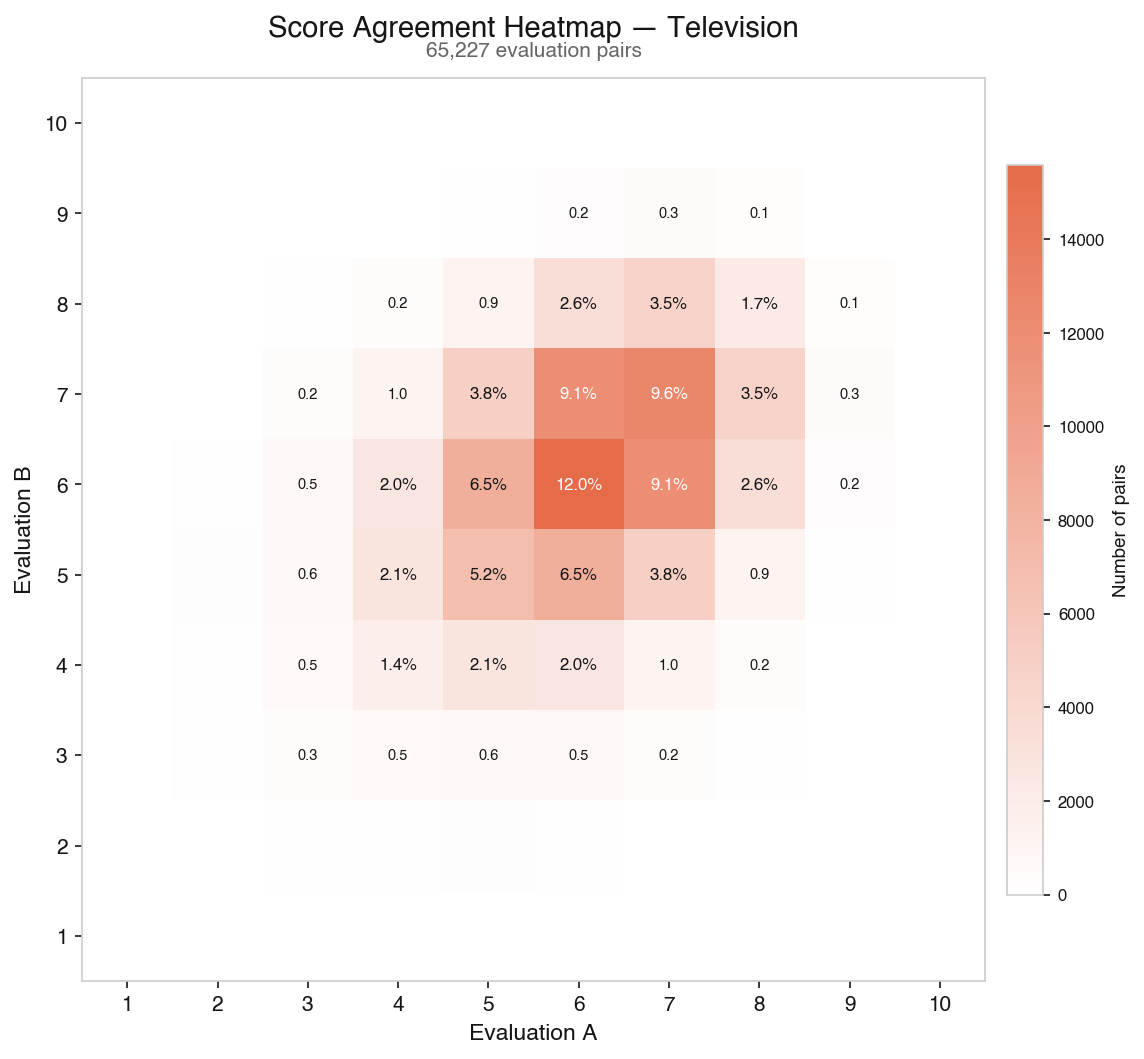
Appendix: Score agreement heatmaps
For those who want to see the full picture of how evaluation pairs distribute, here are heatmaps plotting every pair of scores on overall quality. The dark band along the diagonal is agreement; the further from the line, the rarer the outcome.
Film — 212,673 evaluation pairs:
Television — 65,227 evaluation pairs:
Notes
¹ Though there have been 128,020 evaluations across more than 71,000 projects, not all projects have been evaluated more than once. An evaluation pair means two readers who independently evaluated the same project. A project with two evaluations produces one pair. A project with three produces three. A project with ten produces forty-five. Because many projects on the platform have been evaluated multiple times, 128,020 individual evaluations generate 277,900 unique reader-to-reader comparisons — 212,673 for film and 65,227 for television.
2 Bornmann, L., Mutz, R., & Daniel, H.-D. (2010). “A Reliability-Generalization Study of Journal Peer Reviews: A Multilevel Meta-Analysis of Inter-Rater Reliability and Its Determinants.” PLOS ONE, 5(12), e14331. The study reports inter-rater reliability using the intraclass correlation coefficient (ICC), a statistical measure of how much of the variation in scores reflects real differences between what’s being evaluated versus disagreement between evaluators. An ICC of 1.0 would mean perfect agreement; 0.0 would mean scores are essentially random. The meta-analytic mean across 48 studies was 0.23 (fixed effects) to 0.34 (random effects). https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0014331
3 The ranges in this section represent the 75% confidence interval — the range within which three out of four scores fall relative to the project’s true score. To compute this, we took every project with four or more evaluations, shuffled the evaluation order 100 times, and at each step (one evaluation, two averaged together, three, four) measured how far the running average landed from the project’s final average across all its evaluations. The 75th percentile of those absolute deviations gives the reported range.
4 For the third-reader analysis, we used all projects with exactly three evaluations (4,121 film, 1,571 television). For each project, we considered all three possible designations of which evaluation serves as the “third read.” We then filtered to cases where the other two evaluations diverged by two or more points on overall quality and measured how often the third fell within the range set by those two scores, inclusive of endpoints.
If your first score is a 7, just stop there. Period. My second score was a 2.
Interesting. Two things I’m still unclear on:
Could readers/evaluators see a script’s score on the site before reading it? If yes, I’d expect at least some anchoring.
And what exactly counts as “the same script” here? The same draft, or the same project even if it’s been revised?